“面试知识点整理
C#数据结构解析
ArrayList ,List
ArrayList 和 List 都是不限制长度的集合类型 ,List相比ArrayList 就内部实现而言除了泛型本质没有太大区别。不过为避免装箱拆箱问题,尽可能使用List
集合内部是由数组实现,默认大小是4,但你使用无参构造函数构造实例时,内部数组大小是0,当你加入第一个元素时,才扩容为4,添加元素时,如果发现内置数组大小不够,内置数组大小会扩容为原来的两倍,每一次扩容都会重新开辟一个数组,拷贝旧数组的数据,如果你要给集合添加大量的元素却不为它初始化一个合适容量,频繁的内存开辟和多余的数组拷贝会导致性能的损耗。
所以使用时建议提供合适的容量。
Hashtable,Dictionary
HashTable
Hashtable和Dictionary都是哈希表的实现,很多人说Dictionary内部是由hashtable实现的,这是不恰当的。
Hashtable的构造需要装载因子,装载因子是0.1 到 1.0 范围内的数字 ,是内部存储桶数(count)所占桶数组(buckets)桶数(hashsize)的最大比率 ,当桶数大于装载数(loadsize)时,桶数组就会扩容
hashtable内部解除哈希冲突的算法是双重散列法,是开放地址法中最好的方法之一。
双重散列法
双重散列是线性开型寻址散列(开放寻址法)中的冲突解决技术。这个方法的基本思想是:当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。这个过程可用下式描述:
双重散列使用在发生冲突时将第二个散列函数应用于键的想法。
此算法使用:
(hash1(key) + i * hash2(key)) % TABLE_SIZE
来进行双哈希处理。hash1() 和 hash2() 是哈希函数,而 TABLE_SIZE 是哈希表的大小。当发生碰撞时,我们通过重复增加 步长i 来寻找键。
第一个Hash函数:hash1(key) = key % TABLE_SIZE。
/**
* 计算首次的Hash值
*
* @param key
* @return
*/
private int hash1(int key)
{
return (key % TABLE_SIZE);
}
第二个Hash函数是:hash2(key) = PRIME – (key % PRIME),其中 PRIME 是小于 TABLE_SIZE 的质数。
/**
* 发生碰撞是时继续计算Hash值
*
* @param key
* @return
*/
private int hash2(int key)
{
return (PRIME - (key % PRIME));
}
第二个Hash函数表现好的特征:
- 绝对不会产生 0 索引
- 能在整个HashTable 循环探测
- 计算会快点
- 与第一个Hash函数互相独立
- PRIME 与 TABLE_SIZE 是 “相对质数”

package algorithm.hash;
/**
* 双重哈希
*/
public class DoubleHash {
private static final int TABLE_SIZE = 13; // 哈希表大小
private static int PRIME = 7; // 散列函数值
private int[] hashTable;
private int curr_size; // 当前表中存的元素
public DoubleHash() {
this.hashTable = new int[TABLE_SIZE];
this.curr_size = 0;
for (int i = 0; i < TABLE_SIZE; i++)
hashTable[i] = -1;
}
private boolean isFull() {
return curr_size == TABLE_SIZE;
}
/**
* 计算首次的Hash值
*
* @param key
* @return
*/
private int hash1(int key) {
return (key % TABLE_SIZE);
}
/**
* 发生碰撞是时继续计算Hash值
*
* @param key
* @return
*/
private int hash2(int key) {
return (PRIME - (key % PRIME));
}
/**
* 向Hash表中存值
*
* @param key
*/
private void insertHash(int key) {
/* 表是否已满 */
if (isFull()) {
return;
}
/* 获取首次的Hash值 */
int index = hash1(key);
// 如果发生碰撞
if (hashTable[index] != -1) {
/* 计算第二次的Hash值 */
int index2 = hash2(key);
int i = 1;
while (true) {
/* 再次合成新的地址 */
int newIndex = (index + i * index2) % TABLE_SIZE;
// 如果再次寻找时没有发生碰撞,把key存入表中的对应位置
if (hashTable[newIndex] == -1) {
hashTable[newIndex] = key;
break;
}
i++;
}
} else {
// 一开始没有发生碰撞
hashTable[index] = key;
}
curr_size++; // Hash表中当前所存元素数量加1
}
/**
* 打印Hash表
*/
private void displayHash() {
for (int i = 0; i < TABLE_SIZE; i++) {
if (hashTable[i] != -1)
System.out.println(i + " --> " + hashTable[i]);
else
System.out.println(i);
}
}
public static void main(String[] args) {
int[] a = {19, 27, 36, 10, 64};
DoubleHash doubleHash = new DoubleHash();
for (int i = 0; i < a.length; i++)
doubleHash.insertHash(a[i]);
doubleHash.displayHash();
}
}
Dictionary
而不同的是,Dictionary内部解除哈希冲突的算法是链地址法,而且Dictionary的构造不需要装载因子,不受装载因子的限制 ,如果Dictionary非常小,查找,插入,删除等操作拥有近乎O(1)的效率
和ArrayList ,List类似的是Dictionary和hashtable内部也是由数组实现的,所以构造时也需要提供合适容量,防止性能的损耗。
但我们需要另外注意的是你提供给构造函数的容量不一定会是初始时内置数组的长度,构造函数内部会选择一个大于等于你所选择容量的素数作为真实的初始容量。
我们知道Dictionary的最大特点就是可以通过任意类型的key寻找值。而且是通过索引,速度极快。
该特点主要意义:数组能通过索引快速寻址,其他的集合基本都是以此为基础进行扩展而已。 但其索引值只能是int,某些情境下就显出Dictionary的便利性了。
那么问题就来了–C#是怎么做的呢,能使其做到泛型索引。
我们关注圈中的内容,这是Dictionary的本质 — 两个数组,。这是典型的用空间换取时间的做法。
先来说下两数组分别代表什么。
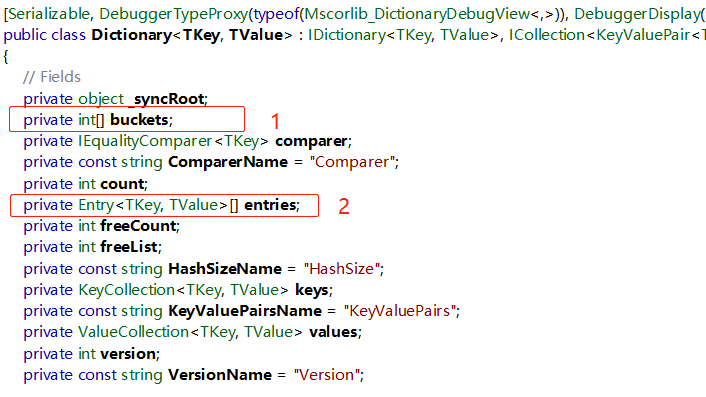
1- buckets,int[] ,水桶!不过我觉得用仓库更为形象。eg: buckets = new int[3]; 表示三个仓库,i = buckets [0] ,if i = -1 表示该仓库为空,否则表示第一个仓库存储着东西。这个东西表示数组entries的索引。
2- entries , Entry<TKey,TValue>[] ,Entry是个结构,key,value就是我们的键值真实值,hashCode是key的哈希值,next可以理解为指针,这里先不具体展开。
[StructLayout(LayoutKind.Sequential)]
private struct Entry
{
public int hashCode;
public int next;
public TKey key;
public TValue value;
}
先说一下索引,如何用人话来解释呢?这么说吧,本身操作系统只支持地址寻址,如数组声明时会先存一个header,同时获取一个base地址指向这个header,其后的元素都是通过*(base+index)来进行寻址。
基于这个共识,Dictionary用泛型key索引的实现就得想方设法把key转换到上面数组索引上去。
也就是说要在记录的存储位置和它的关键字之间建立一个确定的对应关系 f,使每个关键字和结构中一个惟一的存储位置相对应。
因而在查找时,只要根据这个对应关系 f 找到给定值 K 的函数值 f(K)。若结构中存在关键字和 K 相等的记录。在此,我们称这个对应关系 f 为哈希 (Hash) 函数,按这个思想建立的表为哈希表。
回到Dictionary,这个f(K)就存在于key跟buckets之间:
dic[key]加值的实现:entries数组加1,获取i–>key–>获取hashCode–>f(hashCode)–>确定key对应buckets中的某个仓库(buckets对应的索引)–>设置仓库里的东西(entries的索引 = i)
dic[key]取值的实现:key–>获取hashCode–>f(hashCode)–>确定key对应buckets中的某个仓库(buckets对应的索引)–> 获取仓库里的东西(entries的索引i,上面有说到)–>真实的值entries[i]
上面的流程中只有一个(f(K)获取仓库索引)让我们很难受,因为不认识,那现在问题变成了这个f(K)如何实现了。
实现:
int index = hashCode % buckets.Length;
这叫做除留余数法,哈希函数的其中一种实现。如果你自己写一个MyDictionary,可以用其他的哈希函数。
举个例子,假设两数组初始大小为3, this.comparer.GetHashCode(4 & 0x7fffffff = 4:
Dictionary<int, string> dic = new Dictionary<int, string>();
dic.Add(4, "value");
i=0,key=4–> hashCode=4.GetHashCode()=4–> f(hashCode)=4 % 3 = 1–>第1号仓库–>东西 i = 0.
此时两数组状态为:
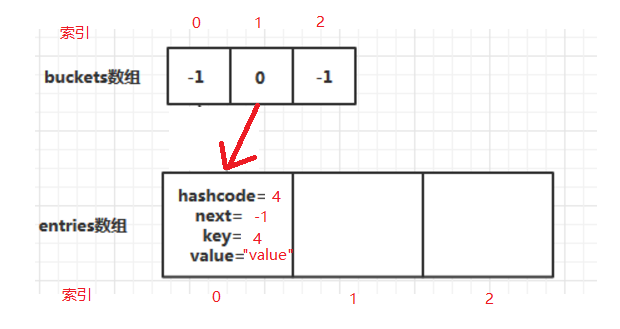
取值按照之前说的顺序进行,仿佛已经完美。但这里还有个问题,不同的key生成的hashCode经过f(K)生成的值不是唯一的。即一个仓库可能会放很多东西。
C#是这么解决的,每次往仓库放东西的时候,先判断有没有东西(buckets[index] 是否为 -1),如果有,则进行修改。
如再:
dic.Add(7, "value");
dic.Add(10, "value");
f(entries[1]. hashCode)=7 % 3 = 1也在第一号仓库,则修改buckets[1] = 1。
同时修改entries[1].next = 0;//上一个仓库的东西
f(entries[2].hashCode)=10 % 3 = 1也在第一号仓库,则再修改buckets[1] = 2。
同时修改entries[1].next = 1;//上一个仓库的东西
这样相当于1号仓库存了一个单向链表,entries:2-1-0。
成功解决。
这里有人如果看过这些集合源码的话知道数组一般会有一个默认大小(当然我们初始化集合的时候也可以手动传入capacity),总之,Length不可能无限大。
那么当集合满的时候,我们需对集合进行扩容,C#一般直接Length*2。那么buckets.Length就是可变的,上面的f(K)结果也就不是恒定的。
C#对此的解决放在了扩容这一步:
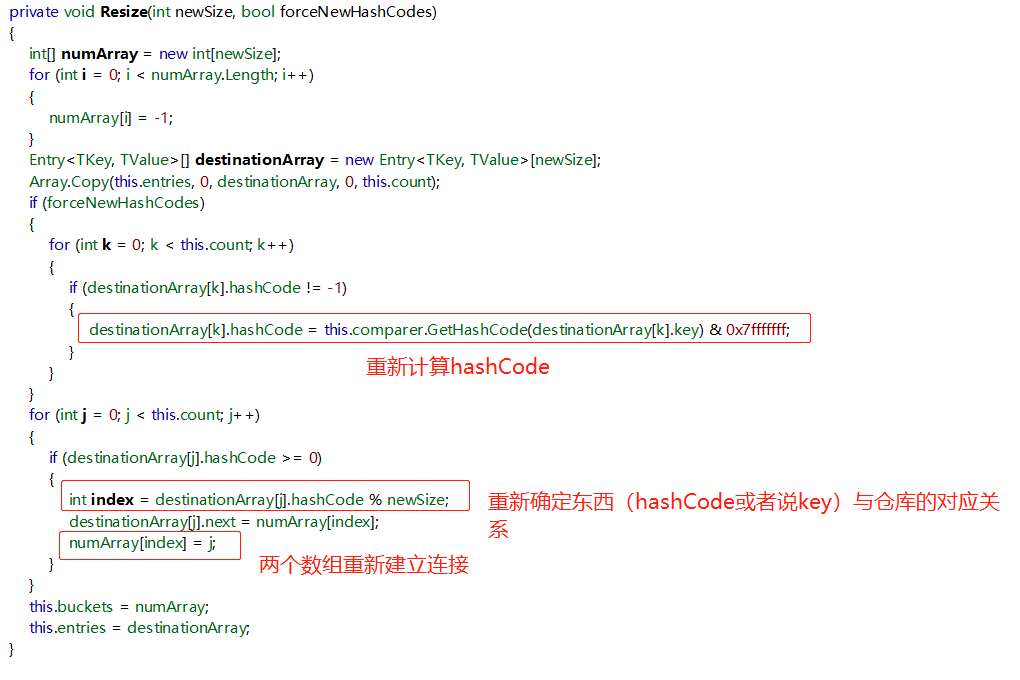
可以看到扩容实质就是新开辟一个更大空间的数组,讲道理是耗资源的。所以我们在初始化集合的时候,每次都给定一个合适的Capacity,讲道理是一个老油条该干的事儿。
上面说的这就是所谓“用空间换取时间的做法”,两个数组存了一个集合,而集合中我们最关心的value仿佛是个主角,一堆配角作陪。
SortedList
SortedList是支持排序的关联性(键值对 )集合 ,内部采用数组实现,所以和List相同的是,初始化时需要提供一个合适的容量,SortedList内部采用哈希算法实现,和Dictionary类似的是,SortedList内部解除哈希冲突的算法是链地址法。
因为在查找的时候利用了二分搜索,所以查找的性能会好一些,时间复杂度是O(log n)
如果你想要快速查找,又想集合按照key的顺序排列,最后这个集合的操作(添加和移除)比较少的话,就是SortedList了
SortedSet,SortedDictioanry
SortedSet类似于HashSet,但略有不同的是,SortedSet是有序排列,SortedSet内部实现应该是所有集合中最复杂,是依靠红黑树的原理实现。
SortedDictioanry和Dictionary的区别与HashSet和SortedSet的区别基本一致,因为SortedDictioanry内部本身就是依靠SortedSet实现的,并且SortDictionary内部顺序是以key的顺序为排列的
public SortedDictionary(IDictionary<TKey,TValue> dictionary, IComparer<TKey> comparer) {
if( dictionary == null) {
ThrowHelper.ThrowArgumentNullException(ExceptionArgument.dictionary);
}
_set = new TreeSet<KeyValuePair<TKey, TValue>>(new KeyValuePairComparer(comparer));
foreach(KeyValuePair<TKey, TValue> pair in dictionary) {
_set.Add(pair);
}
}
LinkedList,Stack,Queue
这3个集合我就不多做解释,完全按这几个基础数据结构的原理来实现。不过Stack,Queue内部采用数组实现,所以也要注意初始化时提供一个恰当的容量啊